|
1 | 1 | ## 1. 递归简介 |
2 | 2 |
|
3 | | -### 1.1 递归的定义 |
| 3 | +> **递归(Recursion)**:指的是一种通过重复将原问题分解为同类的子问题而解决的方法。在绝大数编程语言中,可以通过在函数中再次调用函数自身的方式来实现递归。 |
4 | 4 |
|
5 | | -> **递归(Recursion)**:指的是在函数的定义中直接或间接调用自身的一种方法。它通常把一个大型复杂的问题层层转化为一个与原问题相似的规模较小的问题来求解,递归策略只需少量的程序就可以描述出解题过程所需要的多次重复计算,大大减少了程序的代码量。 |
| 5 | +举个例子来说明一下递归算法。比如阶乘的计算方法在数学上的定义为: |
6 | 6 |
|
7 | | -### 1.2 递归的特点 |
| 7 | +$fact(n) = \begin{cases} 1 & \text{if n = 0} \\ n * fact(n - 1) & \text{if n > 0} \end{cases}$ |
8 | 8 |
|
9 | | -1. 递归就是在过程或函数里调用自身。 |
10 | | -2. 在使用递归策略时,必须有一个明确的递归结束条件,称为递归出口。 |
11 | | -3. 递归算法解题时通常显得很简洁,但递归 算法解题的运行效率较低。 |
12 | | -4. 在递归调用过程中,系统为每层的返回点、局部变量等开辟了栈来存储。递归次数过多容易造成栈溢出等。 |
| 9 | +根据阶乘计算方法的数学定义,我们可以使用调用函数自身的方式来实现阶乘函数 `fact(n)` ,其实现代码可以写作: |
13 | 10 |
|
14 | | -## 2. 递归的应用 |
| 11 | +```Python |
| 12 | +def fact(n): |
| 13 | + if n == 0: |
| 14 | + return 1 |
| 15 | + return n * fact(n - 1) |
| 16 | +``` |
| 17 | + |
| 18 | +以 `n = 6` 为例,上述代码中阶乘函数 `fact(6)` 的计算过程如下: |
| 19 | + |
| 20 | +```Python |
| 21 | +fact(6) |
| 22 | += 6 * fact(5) |
| 23 | += 6 * (5 * fact(4)) |
| 24 | += 6 * (5 * (4 * fact(3))) |
| 25 | += 6 * (5 * (4 * (3 * fact(2)))) |
| 26 | += 6 * (5 * (4 * (3 * (2 * fact(1))))) |
| 27 | += 6 * (5 * (4 * (3 * (2 * (1 * fact(0)))))) |
| 28 | += 6 * (5 * (4 * (3 * (2 * (1 * 1))))) |
| 29 | += 6 * (5 * (4 * (3 * (2 * 1)))) |
| 30 | += 6 * (5 * (4 * (3 * 2))) |
| 31 | += 6 * (5 * (4 * 6)) |
| 32 | += 6 * (5 * 24) |
| 33 | += 6 * 120 |
| 34 | += 720 |
| 35 | +``` |
| 36 | + |
| 37 | +上面的例子也可以用语言描述为: |
| 38 | + |
| 39 | +1. 函数从 `fact(6)` 开始,一层层地调用 `fact(5)`、`fact(4)`、… 一直到最底层的 `fact(0)`。 |
| 40 | +2. 当 `n == 0` 时,`fact(0)` 不再继续调用自身,而是直接向上一层返回结果 `1`。 |
| 41 | +3. `fact(1)` 通过下一层 `fact(0)` 的计算结果得出 `fact(1) = 1 * 1 = 1`,从而向上一层返回结果 `1`。 |
| 42 | +4. `fact(2)` 通过下一层 `fact(1)` 的计算结果得出 `fact(2) = 2 * 1 = 2 `,从而向上一层返回结果 `2`。 |
| 43 | +5. `fact(3)` 通过下一层 `fact(2)` 的计算结果得出 `fact(3) = 3 * 2 = 6 `,从而向上一层返回结果 `6`。 |
| 44 | +6. `fact(4)` 通过下一层 `fact(3)` 的计算结果得出 `fact(4) = 4 * 6 = 24`,从而向上一层返回结果 `24`。 |
| 45 | +7. `fact(5)` 通过下一层 `fact(4)` 的计算结果得出 `fact(5) = 5 * 24 = 120`,从而向上一层返回结果 `120`。 |
| 46 | +8. `fact(6)` 通过下一层 `fact(5)` 的计算结果得出 `fact(6) = 6 * 120 = 720`,从而返回函数的最终结果 `720`。 |
| 47 | + |
| 48 | +这就是阶乘函数的递归计算过程。 |
| 49 | + |
| 50 | +根据上面的描述,我们可以把阶乘函数的递归计算过程分为两个部分: |
| 51 | + |
| 52 | +1. 先逐层向下调用自身,直到达到结束条件(即 `n == 0`)。 |
| 53 | +2. 然后再向上逐层返回结果,直到返回原问题的解(即返回 `fact(6) == 720`)。 |
| 54 | + |
| 55 | +这两个部分也可以叫做「递推过程」和「归回过程」,如下面两幅图所示: |
| 56 | + |
| 57 | +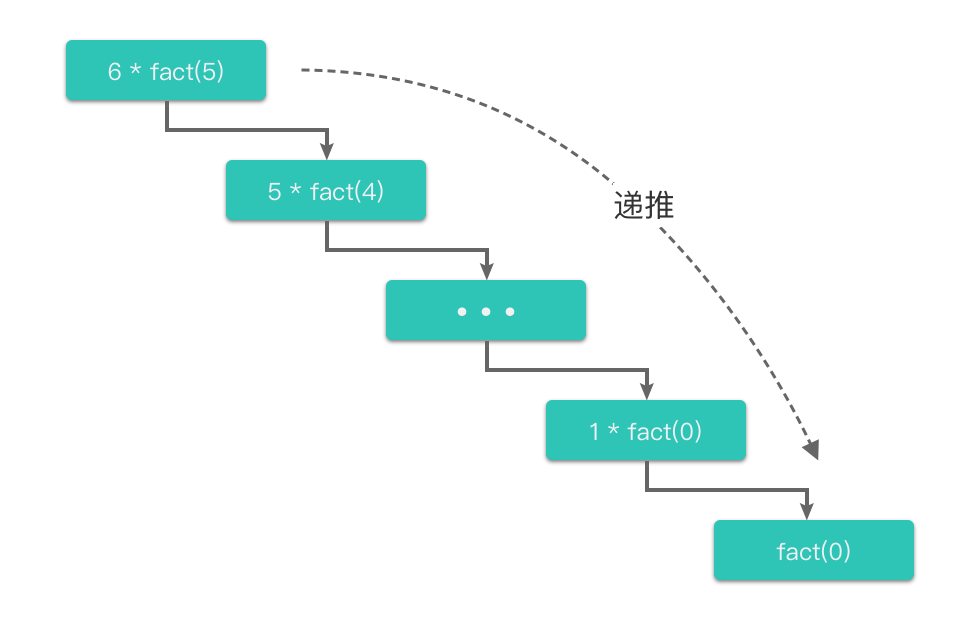 |
| 58 | + |
| 59 | +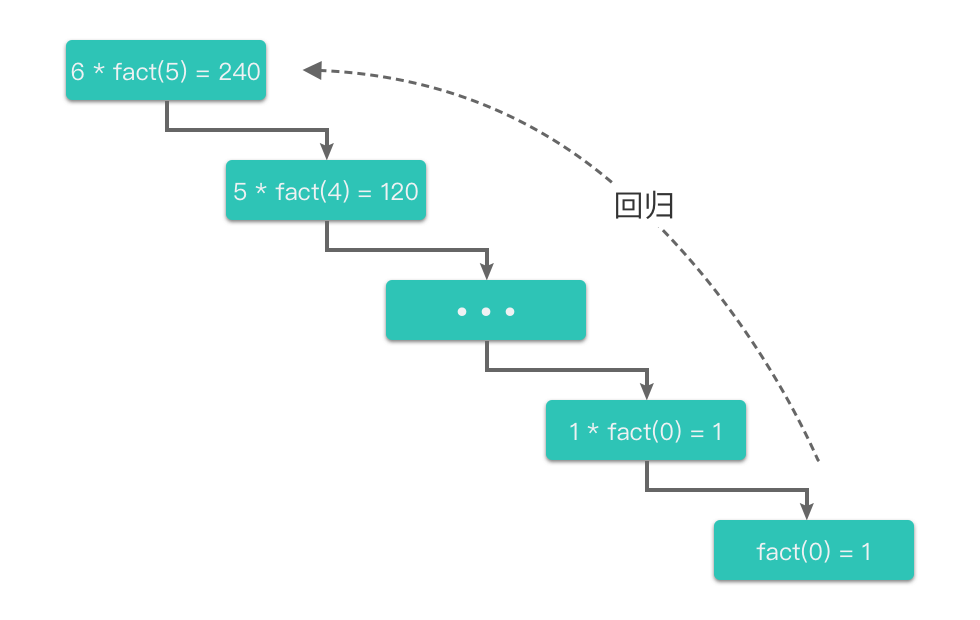 |
| 60 | + |
| 61 | +如上面所说,我们可以把「递归」分为两个部分:「递推过程」和「回归过程」。 |
| 62 | + |
| 63 | +- **递推过程**:指的是将原问题一层一层地分解为与原问题形式相同、规模更小的子问题,直到达到结束条件时停止,此时返回最底层子问题的解。 |
| 64 | +- **回归过程**:指的是从最底层子问题的解开始,逆向逐一回归,最终达到递推开始时的原问题,返回原问题的解。 |
| 65 | + |
| 66 | +「递推过程」和「回归过程」是递归算法的精髓。从这个角度来理解递归,递归的基本思想就是: **把规模大的问题不断分解为子问题来解决。** |
| 67 | + |
| 68 | +同时,因为解决原问题和不同规模的小问题往往使用的是相同的方法,所以就产生了函数调用函数自身的情况,这也是递归的定义所在。 |
| 69 | + |
| 70 | +## 2. 递归和数学归纳法 |
| 71 | + |
| 72 | +递归的数学模型其实就是「数学归纳法」。这里简单复习一下数学归纳法的证明步骤: |
| 73 | + |
| 74 | +1. 证明当 `n = b` (`b` 为基本情况,通常为 `0` 或者 `1`)时,命题成立。 |
| 75 | +2. 证明当 `n > b` 时,假设 `n = k` 时命题成立,那么可以推导出 `n = k + 1` 时命题成立。这一步不是直接证明的,而是先假设 `n = k` 时命题成立,利用这个条件,可以推论出 `n = k + 1` 时命题成立。 |
| 76 | + |
| 77 | +通过以上两步证明,就可以说:当 `n >= b` 时,命题都成立。 |
| 78 | + |
| 79 | +我们可以从「数学归纳法」的角度来解释递归: |
| 80 | + |
| 81 | +- **递归终止条件**:数学归纳法第一步中的 `n = b` ,可以直接得出结果。 |
| 82 | +- **递推过程**:数学归纳法第二步中的假设部分(假设 `n = k` 时命题成立),也就是假设我们当前已经知道了 `n = k` 时的计算结果。 |
| 83 | +- **回归过程**:数学归纳法第二步中的推论部分(根据 `n = k` 推论出 `n = k + 1`),也就是根据下一层的结果,计算出上一层的结果。 |
| 84 | + |
| 85 | +事实上,数学归纳法的思考过程也正是在解决某些数列问题时,可以使用递归算法的原因。比如阶乘、数组前 `n` 项和、斐波那契数列等等。 |
| 86 | + |
| 87 | +## 3. 递归三步走 |
| 88 | + |
| 89 | +上面我们提到,递归的基本思想就是: **把规模大的问题不断分解为子问题来解决。** 那么,在写递归的时候,我们可以按照这个思想来书写递归,具体步骤如下: |
| 90 | + |
| 91 | +1. **写出递推公式**:找到将原问题分解为子问题的规律,并且根据规律写出递推公式。 |
| 92 | +2. **明确终止条件**:推敲出递归的终止条件,以及递归终止时的处理方法。 |
| 93 | +3. **将递推公式和终止条件翻译成代码**: |
| 94 | + 1. 定义递归函数(明确函数意义、传入参数、返回结果等)。 |
| 95 | + 2. 书写递归柱体(提取重复的逻辑,缩小问题规模)。 |
| 96 | + 3. 明确递归终止条件(给出递归终止条件,以及递归终止时的处理方法)。 |
| 97 | + |
| 98 | +### 3.1 写出递推公式 |
| 99 | + |
| 100 | +写出递推公式的关键在于:**找到将原问题分解为子问题的规律,并将其抽象成递推公式**。 |
| 101 | + |
| 102 | +我们在思考递归的逻辑时,没有必要在大脑中将整个递推过程和回归过程一层层地想透彻。很可能还没有递推到栈底呢,脑子就已经先绕晕了。 |
| 103 | + |
| 104 | +之前讲解的阶乘例子中,一个问题只需要分解为一个子问题,我们很容易能够想清楚「递推过程」和「回归过程」的每一个步骤,所以写起来和理解起来都不难。 |
| 105 | + |
| 106 | +但是当我们面对的是一个问题需要分解为多个子问题的情况时,就没有那么容易想清楚「递推过程」和「回归过程」的每一个步骤了。 |
| 107 | + |
| 108 | +那么我们应该如何思考「递推过程」和「回归过程」呢,又该如何写出递归中的递推公式呢? |
| 109 | + |
| 110 | +如果一个问题 A,可以分解为若干个规模较小、与原问题形式相同的子问题 B、C、D,那么这些子问题就可以用相同的解题思路来解决。我们可以假设 B、C、D 已经解决了,然后只需要考虑在这个基础上去思考如何解决问题 A 即可。不需要再一层层往下思考子问题与子子问题、子子问题与子子子问题之间的关系。这样理解起来就简单多了。 |
| 111 | + |
| 112 | +从问题 A 到分解为子问题 B、C、D 的思考过程其实就是递归的「递推过程」。而从子问题 B、C、D 的解到问题 A 的解的思考过程其实就是递归的「回归过程」。想清楚了「如何划分子问题」和「如何通过子问题来解决原问题」这两个过程,也就想清楚了递归的「递推过程」和「回归过程」。 |
| 113 | + |
| 114 | +然后,我们只需要考虑原问题与子问题之间的关系,就能够在此基础上,写出递推公式了。 |
| 115 | + |
| 116 | +### 3.2 明确终止条件 |
| 117 | + |
| 118 | +递归的终止条件也叫做递归出口。在写出了递推公式之后,就要考虑递归的终止条件是什么。如果没有递归的终止条件,函数就会无限地递归下去,程序就会失控崩溃了。通常情况下,递归的终止条件是问题的边界值。 |
| 119 | + |
| 120 | +在找到递归的终止条件时,我们应该直接给出该条件下的处理方法。一般地,在这种情境下,问题的解决方案是直观的、容易的。例如阶乘中 `fact(0) = 1`。斐波那契数列中 `f(1) = 1, f(2) = 2`。 |
| 121 | + |
| 122 | +### 3.3 将递推公式和终止条件翻译成代码 |
| 123 | + |
| 124 | +在写出递推公式和明确终止条件之后,我们就可以将其翻译成代码了。这一步也可以分为 3 步来做: |
| 125 | + |
| 126 | +1. 定义递归函数:明确函数意义、传入参数、返回结果等。 |
| 127 | +2. 书写递归主体:提取重复的逻辑,缩小问题规模。 |
| 128 | +3. 明确递归终止条件:给出递归终止条件,以及递归终止时的处理方法。 |
| 129 | + |
| 130 | +#### 3.3.1 定义递归函数 |
| 131 | + |
| 132 | +在定义递归函数时,一定要明确递归函数的意义,也就是要明白这个问题传入的参数是什么,最终返回的结果是要解决的什么问题。 |
| 133 | + |
| 134 | +比如说阶乘函数 `fact(n)`,这个函数的传入参数是问题的规模 `n`,最终返回的结果是 `n` 的阶乘值。 |
| 135 | + |
| 136 | +#### 3.3.2 书写递归主体 |
| 137 | + |
| 138 | +在将原问题划分为子问题,并根据原问题和子问题的关系,我们就可以推论出对应的递推公式。然后根据递推公式,就可以将其转换为递归的主体代码。 |
| 139 | + |
| 140 | +#### 3.3.3 明确递归终止条件 |
| 141 | + |
| 142 | +这一步其实就是将「3.2 明确终止条件」章节中的递归终止条件和终止条件下的处理方法转换为代码中的条件语句和对应的执行语句。 |
| 143 | + |
| 144 | +#### 3.3.4 递归伪代码 |
| 145 | + |
| 146 | +根据上述递归书写的步骤,我们就可以写出递归算法的代码了。递归算法的伪代码如下: |
| 147 | + |
| 148 | +```Python |
| 149 | +def recursion(大规模问题): |
| 150 | + if 递归终止条件: |
| 151 | + 递归终止时的处理方法 |
| 152 | + |
| 153 | + return recursion(小规模问题) |
| 154 | +``` |
| 155 | + |
| 156 | +## 4. 递归的注意点 |
| 157 | + |
| 158 | +### 4.1 避免栈溢出 |
| 159 | + |
| 160 | +在程序执行中,递归是利用堆栈来实现的。每一次递推都需要一个栈空间来保存调用记录,每当进入一次函数调用,栈空间就会加一层栈帧。每一次回归,栈空间就会减一层栈帧。由于系统中的栈空间大小不是无限的,所以,如果递归调用的次数过多,会导致栈空间溢出。 |
| 161 | + |
| 162 | +为了避免栈溢出,我们可以在代码中限制递归调用的最大深度来解决问题。当递归调用超过一定深度时(比如 100)之后,不再进行递归,而是直接返回报错。 |
| 163 | + |
| 164 | +当然这种做法并不能完全避免栈溢出,也无法完全解决问题,因为系统允许的最大递归深度跟当前剩余的占空间有关,事先无法计算。 |
| 165 | + |
| 166 | +如果使用递归算法实在无法解决问题,我们可以考虑将递归算法变为非递归算法(即递推算法)来解决栈溢出的问题。 |
| 167 | + |
| 168 | +### 4.2 避免重复运算 |
| 169 | + |
| 170 | +在使用递归算法时,还可能会出现重复运算的问题。比如斐波那契数列的定义是:`f(1) = 1, f(2) = 2, f(n) = f(n - 1) + f(n - 2)`。对应的递推过程如下图所示: |
| 171 | + |
| 172 | + |
| 173 | + |
| 174 | +从图中,我们可以看到:想要计算 `f(5)`,需要先计算 `f(4)` 和 `f(3)`,而在计算 `f(4)` 时还需要计算 `f(3)`。这样 `f(3)` 就进行了多次计算,这就是重复计算问题。 |
| 175 | + |
| 176 | +为了避免重复计算,我们可以使用哈希表、集合、列表等结构来保存已经求解过的 `f(k)` 的结果。当递归调用用到 `f(k)` 时,先查看一下之前是否已经计算过结果,如果已经计算过,则直接从对应结构中取值返回,而不用再递推下去,这样就避免了重复计算问题。 |
| 177 | + |
| 178 | +## 5. 递归的应用 |
| 179 | + |
| 180 | +### 5.1 斐波那契数 |
| 181 | + |
| 182 | +#### 5.1.1 题目链接 |
| 183 | + |
| 184 | +- [509. 斐波那契数 - 力扣(LeetCode)](https://leetcode-cn.com/problems/fibonacci-number/) |
| 185 | + |
| 186 | +#### 5.1.2 题目大意 |
| 187 | + |
| 188 | +**描述**:给定一个整数 `n`。 |
| 189 | + |
| 190 | +**要求**:计算第 `n` 个斐波那契数。 |
| 191 | + |
| 192 | +**说明**: |
| 193 | + |
| 194 | +- 斐波那契数列的定义如下: |
| 195 | + - `f(0) = 0, f(1) = 1`。 |
| 196 | + - `f(n) = f(n - 1) + f(n - 2)`,其中 `n > 1`。 |
| 197 | + |
| 198 | + |
| 199 | +**示例**: |
| 200 | + |
| 201 | +```Python |
| 202 | +输入 n = 2 |
| 203 | +输出 1 |
| 204 | +解释 f(2) = f(1) + f(0) = 1 + 0 = 1 |
| 205 | +``` |
| 206 | + |
| 207 | +#### 5.1.3 解题思路 |
| 208 | + |
| 209 | +根据我们的递推三步走策略,写出对应的递归代码。 |
| 210 | + |
| 211 | +1. 写出递推公式:`f(n) = f(n - 1) + f(n - 2)`。 |
| 212 | +2. 明确终止条件:`f(0) = 0, f(1) = 1`。 |
| 213 | +3. 翻译为递归代码: |
| 214 | + 1. 定义递归函数:`fib(self, n)` 表示输入参数为问题的规模 `n`,返回结果为第 `n` 个斐波那契数。 |
| 215 | + 2. 书写递归主体:`return self.fib(n - 1) + self.fib(n - 2)`。 |
| 216 | + 3. 明确递归终止条件: |
| 217 | + 1. `if n == 0: return 0` |
| 218 | + 2. `if n == 1: return 1` |
| 219 | + |
| 220 | +#### 5.1.4 代码 |
| 221 | + |
| 222 | +```Python |
| 223 | +class Solution: |
| 224 | + def fib(self, n: int) -> int: |
| 225 | + if n == 0: |
| 226 | + return 0 |
| 227 | + if n == 1: |
| 228 | + return 1 |
| 229 | + return self.fib(n - 1) + self.fib(n - 2) |
| 230 | +``` |
| 231 | + |
| 232 | +### 5.2 二叉树的最大深度 |
| 233 | + |
| 234 | +#### 5.2.1 题目链接 |
| 235 | + |
| 236 | +- [104. 二叉树的最大深度 - 力扣(LeetCode)](https://leetcode-cn.com/problems/maximum-depth-of-binary-tree/) |
| 237 | + |
| 238 | +#### 5.2.2 题目大意 |
| 239 | + |
| 240 | +**描述**:给定一个二叉树的根节点 `root`。 |
| 241 | + |
| 242 | +**要求**:找出该二叉树的最大深度。 |
| 243 | + |
| 244 | +**说明**: |
| 245 | + |
| 246 | +- 二叉树的深度:根节点到最远叶子节点的最长路径上的节点数。 |
| 247 | +- 叶子节点:没有子节点的节点。 |
| 248 | + |
| 249 | +**示例**: |
| 250 | + |
| 251 | +```Python |
| 252 | +输入 [3,9,20,null,null,15,7] |
| 253 | +对应二叉树 |
| 254 | + 3 |
| 255 | + / \ |
| 256 | + 9 20 |
| 257 | + / \ |
| 258 | + 15 7 |
| 259 | +输出 3 |
| 260 | +解释 该二叉树的最大深度为 3 |
| 261 | +``` |
| 262 | + |
| 263 | +#### 5.2.3 解题思路 |
| 264 | + |
| 265 | +根据递归三步走策略,写出对应的递归代码。 |
| 266 | + |
| 267 | +1. 写出递推公式:`当前二叉树的最大深度 = max(当前二叉树左子树的最大深度, 当前二叉树右子树的最大深度) + 1`。 |
| 268 | + - 即:先得到左右子树的高度,在计算当前节点的高度。 |
| 269 | +2. 明确终止条件:当前二叉树为空。 |
| 270 | +3. 翻译为递归代码: |
| 271 | + 1. 定义递归函数:`maxDepth(self, root)` 表示输入参数为二叉树的根节点 `root`,返回结果为该二叉树的最大深度。 |
| 272 | + 2. 书写递归主体:`return max(self.maxDepth(root.left) + self.maxDepth(root.right))`。 |
| 273 | + 3. 明确递归终止条件:`if not root: return 0` |
| 274 | + |
| 275 | +#### 5.2.4 代码 |
| 276 | + |
| 277 | +```Python |
| 278 | +class Solution: |
| 279 | + def maxDepth(self, root: Optional[TreeNode]) -> int: |
| 280 | + if not root: |
| 281 | + return 0 |
| 282 | + |
| 283 | + return max(self.maxDepth(root.left), self.maxDepth(root.right)) + 1 |
| 284 | +``` |
15 | 285 |
|
16 | 286 | ## 参考资料 |
17 | 287 |
|
18 | | -- 【书籍】算法竞赛入门经典:训练指南 - 刘汝佳,陈锋 著 |
| 288 | +- 【书籍】算法竞赛入门经典:训练指南 - 刘汝佳,陈锋 著 |
| 289 | +- 【问答】[对于递归有没有什么好的理解方法? - 知乎 - 方应杭](https://www.zhihu.com/question/31412436/answer/738989709) |
| 290 | +- 【问答】[对于递归有没有什么好的理解方法? - 知乎 - 老刘](https://www.zhihu.com/question/31412436/answer/724915708) |
| 291 | +- 【博文】[递归 & 分治 - OI Wiki](https://oi-wiki.org/basic/divide-and-conquer/) |
| 292 | +- 【博文】[递归详解 - labuladong](https://github.com/labuladong/fucking-algorithm/blob/master/算法思维系列/递归详解.md) |
0 commit comments